Empty searches and hacking URLs
Empty searches and hacking URLs#
Search interfaces present us with a set of options designed to structure our search experience in particular ways. For example, if you wanted to find out how many digitised newspaper articles are currently in Trove, you might try an empty search – a search with no keyword value. An empty search should return everything in the collection. But if you attempt this in the Trove web interface you’ll find that the search button remains disabled until you type something in the box. It just won’t let you.
This limitation is imposed by the interface, not the underlying search technologies. If you want to run an empty search you can bypass the interface with a little harmless url hacking. Try this:
Head to Trove newspapers, type anything in the search box, and hit the search button.
Now look at the url in your browser’s location bar. You should see something like:
https://trove.nla.gov.au/search/category/newspapers?keyword=anything
Delete everything after the equals sign, so you end up with:
https://trove.nla.gov.au/search/category/newspapers?keyword=
Hit enter to submit the edited url.
You should now have more than 200 million search results. I just tried this myself and Trove told me there were 238,671,495 newspaper articles – I think that’s everything!
Many collection interfaces impose these sorts of limits, and it can be very frustrating when the web designer’s expectations of our needs don’t match what we want to do. But it’s important to remember that the web page in our browser is just an intermediary between us and the server that actually delivers the data. The interface translates our search preferences into urls and fires them off to the server. When we edited the Trove url above, we were changing the instructions being sent to the server.
If you try to run an empty search in the State Library of NSW’s catalogue you’ll receive a polite reminder to enter a search term. Once again just search for anything and then look closely at the url.
https://collection.sl.nsw.gov.au/search?search=anything
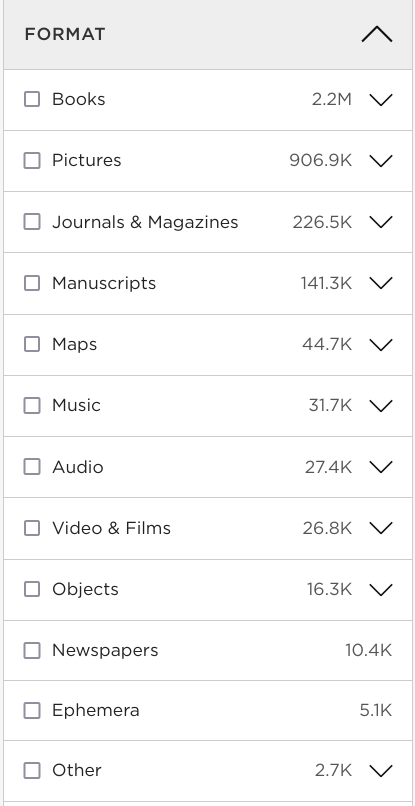
Fig. 1 SLNSW by format#
Yep, you guessed it. By deleting everything after the equals sign we can again bypass the interface and tell the server to give us everything.
https://collection.sl.nsw.gov.au/search?search=
Empty searches are useful because they help you understand what’s lurking behind the search box. To find relevant parts of a collection, it often helps to zoom out and see the whole. In this case, we can see how the State Library’s collection breaks down by format.
But there’s other things you can do by url hacking. You might notice that the State Library catalogue gives you an option to change the number of search results delivered. If we select ‘50 per page’ the search url changes.
https://collection.sl.nsw.gov.au/search?search=&limit=50
The limit parameter is telling the server how many results to return. But the interface only lets us set it to 20, 50, or 100. Try editing the url to set the limit value to 2, or 200, or some other number. By watching how search urls change, we can learn the language we need to communicate with servers directly.
However, the communication between interface and server isn’t always so transparent. Often data is retrieved from the server using Javascript and loaded within the current page. This can mean your browser’s url doesn’t always display the full range of parameters being sent to the server. Most web browsers include a set of developer tools that help you look at what’s going on beneath the surface. By looking at the network activity when we run a Trove search, we can see that requests are sent via Javascript to an internal API.
https://trove.nla.gov.au/api/search/137?terms=&limits={"date.from":[null],"date.to":[null]}&pageSize=20
This is interesting. While Trove’s web interface doesn’t give you an option to change the number of results per page, it looks like a default value is sent to the server using the pageSize parameter. So what happens if we add this parameter to our search url? Does the value get passed on to the internal API? Let’s try.
https://trove.nla.gov.au/search/category/newspapers?keyword=&pageSize=100
Here’s the results. As you can see, it works! By simply adding &pageSize=[some number] to search urls in Trove you can control the number of results per page.
As you explore GLAM collections keep an eye on the urls that your search requests generate. What parameters do they contain, and what do they do? Experiment. Try changing some of the values. The worst that will happen is a server error. But experimenting might open up some options that the search interface is hiding.